
Indexed In
- RefSeek
- Hamdard University
- EBSCO A-Z
- OCLC- WorldCat
- SWB online catalog
- Publons
- International committee of medical journals editors (ICMJE)
- Geneva Foundation for Medical Education and Research
Useful Links
Share This Page
Open Access Journals
- Agri and Aquaculture
- Biochemistry
- Bioinformatics & Systems Biology
- Business & Management
- Chemistry
- Clinical Sciences
- Engineering
- Food & Nutrition
- General Science
- Genetics & Molecular Biology
- Immunology & Microbiology
- Medical Sciences
- Neuroscience & Psychology
- Nursing & Health Care
- Pharmaceutical Sciences
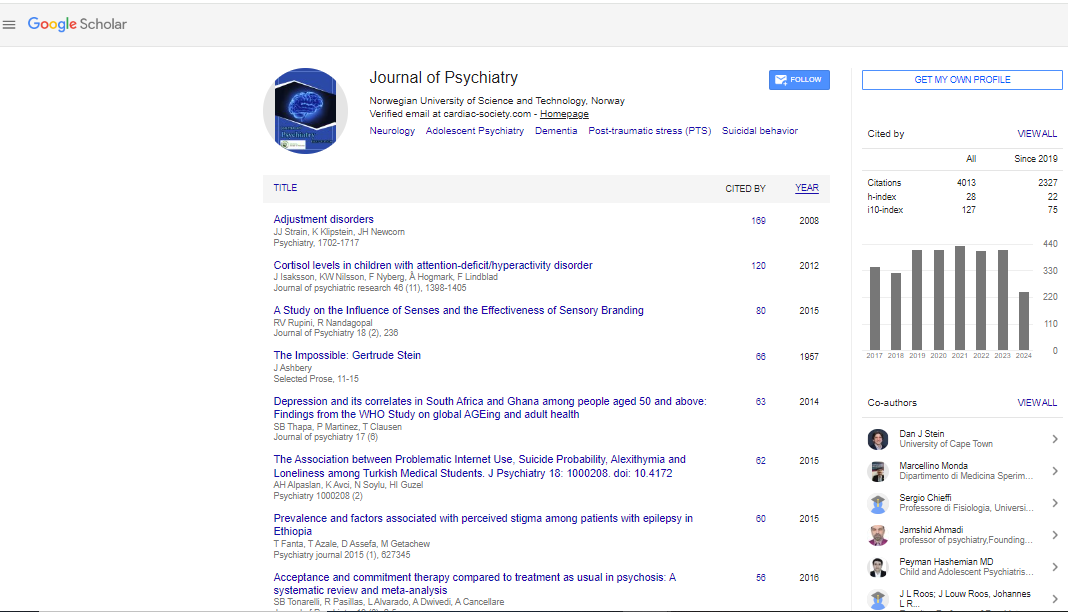
Diagnosis of alcohol use disorder using biomarkers and sociodemographic information. Designing a predictive model using data science
Annual World Congress on Psychiatry
July 11, 2022 | Webinar
Juana Pinar-Sanchez
Meseguer General University Hospital morales, Spain
Scientific Tracks Abstracts: J Psychiatry
Abstract:
The diagnosis of alcohol use disorder (AUD) remains a difficult challenge, and some patients may not be adequately diagnosed. This study aims to identify an optimum combination of laboratory markers to detect risky alcohol consumption, using data science. Other articles have done some similar studies.This is an analytical observational study with 337 subjects (253 men and 83 women, with a mean’s age of 44 years (10,61 SD)). The first group included 204 participants that were following treatment in the Addictive Behaviors Unit (ABU) from Albacete (Spain). They met the diagnostic criteria for AUD specified in DSM-V. The second group included 133 blood donors (people with no risk of AUD), recruited by cross section.For the predictive model, all participants also were divided in two groups, according to the WHO classification for risk alcohol consumption in Spain, that is, males drinking more than 28 standard drink units (SDUs) weekly or women drinking more than 17 SDUs per week. No one from blood donors passed the cut point, since they were mostly no risk drinkers. Some of the AUD group drank below the SDUs cut-point, so they were tagged as “no risk”, a label used by the learned predictive models.Medical history and laboratory markers were selected from our hospital’s database. A correlation between alterations in laboratory markers and the amount of alcohol consumed was established. We then created three predicted models (with logistic regression, classification tree, and Bayesian network) to detect risk alcohol consumption by using laboratory markers as predictive features.The logistic regression model provided an AUD prediction accuracy of 84.8%. A model using 15 statistical significant variables yielded a classification accuracy of 85,1%. We also used a machine-learning based feature selection approach, resulting in an accuracy of 84.8%. Secondly, a classification tree provided a lower accuracy of 79,4%, but easier interpretation. Finally, with Naive Bayes network had an accuracy of 87.5%.By combining several biochemical markers, clinical history (study level), and machine learning, we can enhance the detection of AUD, helping to prevent future complications from alcohol use. Our best predictive model to predict risky alcohol consumption, with an accuracy of 87.5%, using a Bayesian network, selected the best combination of nine biomarkers (basophils, creatinine, alkaline phosphatase, gamma-glutamyl transferase, mean corpuscular haemoglobin, hematocrit, red blood cells distribution width, lactate dehydrogenase, and urea) and the study’s level, being able to predict if the biomarkers alterations of our patients could be secondary to alcohol consumption.
Biography :
She got the Bachelor of Medicine from the University of Valladolid. Currently she is finishing the PhD like a doctoral student at Castilla-La Mancha University in an innovative work project for the detection of alcohol consumption from altered biomarkers. Nowadays she works fulltime in the internal medicine department, in the Morales Meseguer University General Hospital (Murcia, Spain).