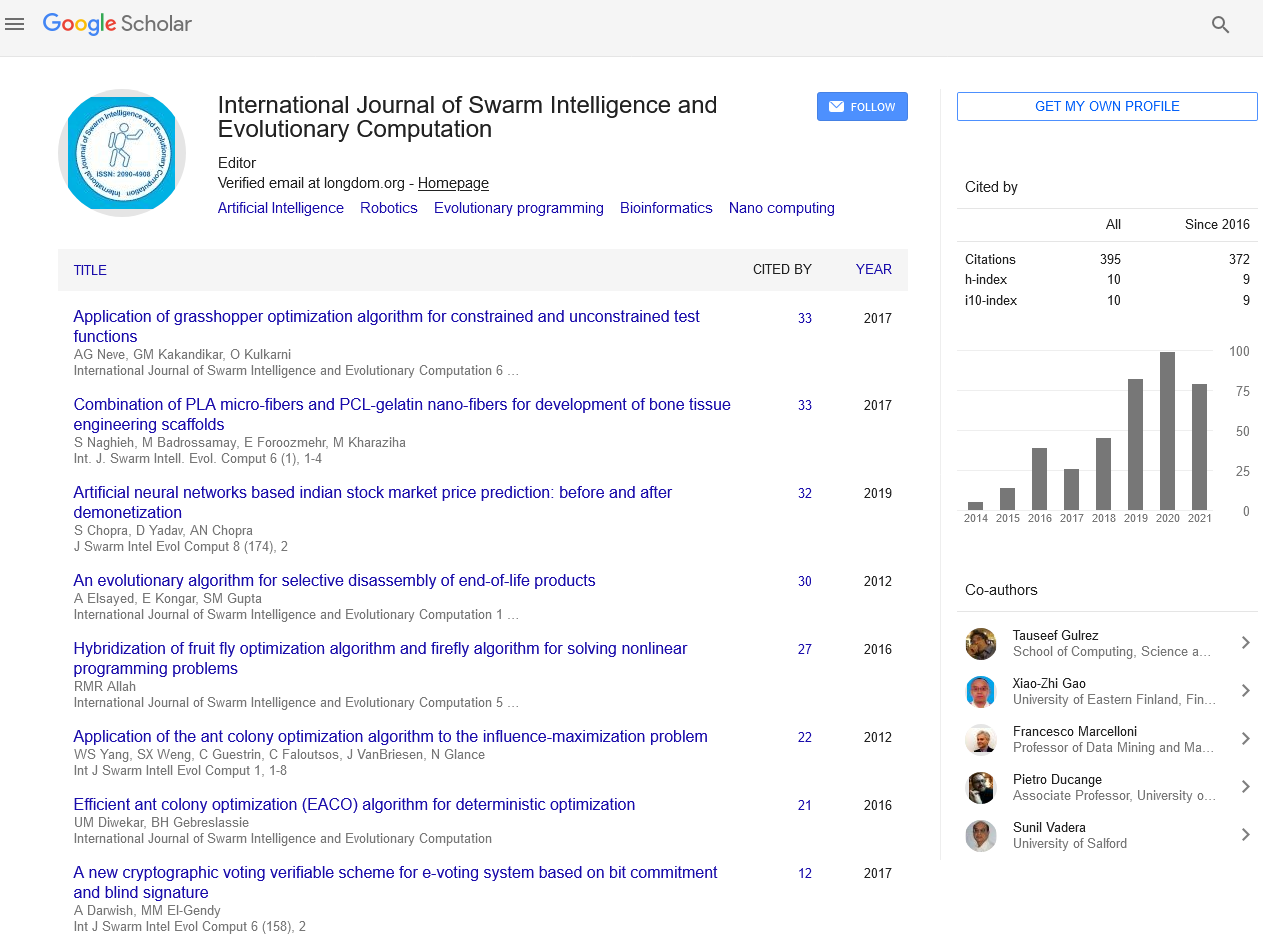

Indexed In
- Genamics JournalSeek
- RefSeek
- Hamdard University
- EBSCO A-Z
- OCLC- WorldCat
- Publons
- Euro Pub
- Google Scholar
Useful Links
Share This Page
Journal Flyer

Open Access Journals
- Agri and Aquaculture
- Biochemistry
- Bioinformatics & Systems Biology
- Business & Management
- Chemistry
- Clinical Sciences
- Engineering
- Food & Nutrition
- General Science
- Genetics & Molecular Biology
- Immunology & Microbiology
- Medical Sciences
- Neuroscience & Psychology
- Nursing & Health Care
- Pharmaceutical Sciences
Commentary - (2022) Volume 11, Issue 2
Role of Algorithms in Machine Learning
Kartheek Varma*Received: 07-Feb-2022, Manuscript No. SIEC-22-15901; Editor assigned: 09-Feb-2022, Pre QC No. SIEC-22-15901(PQ); Reviewed: 23-Feb-2022, QC No. SIEC-22-15901; Revised: 28-Feb-2022, Manuscript No. SIEC-22-15901(R); Published: 07-Mar-2022, DOI: 10.35248/2090-4908.22.11.239
Description
A Machine Learning algorithm, which is a part of AI, uses an assortment of accurate, probabilistic, and upgraded techniques that empower computers to pick up from the past point of reference and perceive hard to perceive patterns from massive, noisy, or complex data.
Machine Learning Methods
Supervised ML algorithm
It is a type of Machine Learning technique that can be applied according to what was previously learned to get new data using labeled data and to predict future events or labels. In this type of learning, supervisor (labels) is present to guide or correct. For this first analysis, the known training set and then the output values are predicted using the learning algorithm [1]. The output defined by the learning system can be compared with the actual output; if errors are identified, they can be rectified and the model can be modified accordingly.
Unsupervised ML algorithm
In this type, there is no supervisor to guide or correct. This type of learning algorithm is used when unlabeled or unclassified information is present to train the system. The system does not define the correct output, but it explores the data in such a way that it can draw inferences (rules) from data sets and can describe hidden structures from unlabeled data.
Semi supervised ML algorithm
These are algorithms that are between the category of supervised and unsupervised learning [2]. Thus, this type of learning algorithm uses both unlabeled and labeled data for training purposes, generally a small amount of labeled data and a large amount of unlabeled data. This type of method is used to improve the accuracy of learning.
Reinforcement ML algorithm
In this type of learning method that gives rewards or punishment on the basis of the work performed by the system. If we train the system to perform a certain task and it fails to do that, the system might be punished; if it performs perfectly, it will be rewarded. It typically works on 0 and 1, in which 0 indicates a punishment and 1 indicates a reward.
Probability Theory of Machine Learning
Machine learning algorithms employ probability theory in their foundations. The probability of an event is a measure of the likelihood of it occurring in a random experiment, which is a number between 0 and 1, where 0 indicates impossibility and 1 indicates certainty. Additionally, the conditional probability is a measure of the probability of an event if another event has already occurred. The most common and popular machine learning algorithms are
Naive bayes classification algorithm (classification by supervised learning)
The naive bayes classifier is based on bayes’ theorem and classifies all values as independent of all other values. This allows you to use probabilities to predict classes / categories based on a particular set of characteristics.
K-means clustering algorithm (unsupervised learning clustering)
The K-Means clustering algorithm [3] is a type of unsupervised learning used to classify unlabeled data, that is, data without defined categories or groups. The algorithm works by finding a group in the data. Here, the number of groups is represented by the variable K. Then it works repeatedly to assign each data point to one.
Support for vector machine algorithms (monitoring learning classification)
Support vector machine algorithms are monitored learning models that analyze data used for classification analysis and regression analysis [4]. They substantially filter data in a category that provides a set of training examples, and each set belongs to one or the other of two categories. The algorithm then works to build a model to assign categories or other new values.
Linear regression (monitored learning / regression)
Linear regression is the most basic regression type. Simple linear regression makes it possible to understand the relationship between two consecutive variables [5].
REFERENCES
- Ackley DH, Hinton GE, Sejnowski TJ. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985;9(1):147-69.
[Crossref], [Google Scholar]
- Figueiredo MA, Jain AK. Unsupervised learning of finite mixture models. IEEE Trans Pattern Anal Mach Intell. 2002;24(3):381-96.
[Crossref], [Google Scholar]
- Likas A, Vlassis N, Verbeek JJ. The global k-means clustering algorithm. Pattern recognition. 2003;36(2):451-61.
[Crossref], [Google Scholar]
- Liang KY, Zeger SL. Regression analysis for correlated data. Annu Rev Public Health. 1993;14(1):43-68.
[Crossref], [Google Scholar], [Indexed]
- Paulo JA, Pereira H, Tomé M. Analysis of variables influencing tree cork caliper in two consecutive cork extractions using cork growth index modelling. Agrofor. Syst. 2017;91(2):221-37.
[Crossref], [Google Scholar]
Citation: Varma K (2022) Role of Algorithms in Machine Learning. Int J Swarm Evol Comput. 11:239.
Copyright: © 2022 Varma K. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.